El modelo COCOMO 1 se basa en la fórmula de reutilización lineal donde la estructura es simplemente un procedimiento y se predice un conjunto estable de requisitos. Por el contrario, el COCOMO 2 se basa en el modelo de reutilización no lineal que proporciona características como la autocalibración y la reutilización del código.
En COCOMO 1, el tamaño del software se expresa mediante líneas de código. Por el contrario, COCOMO 2 proporciona más factores para expresar el tamaño del software, como puntos de objeto, línea de código y también puntos de función.
Existen tres submodelos en COCOMO 1 (es decir, básico, intermedio, avanzado), mientras que en COCOMO 2 son 4 (modelo de desarrollo de aplicaciones, modelo de diseño inicial, modelo de reutilización y modelo post-arquitectónico).
COCOMO 2 utiliza 17 números de generadores de costos. Por el contrario, COCOMO 1 utiliza 15 generadores de costos.
No se utilizan factores de escala en COCOMO 1, mientras que COCOMO 2 emplea los factores de escala para estimar el esfuerzo.
COCOMO 2 puede mitigar el nivel de riesgo en comparación con el modelo COCOMO 1.
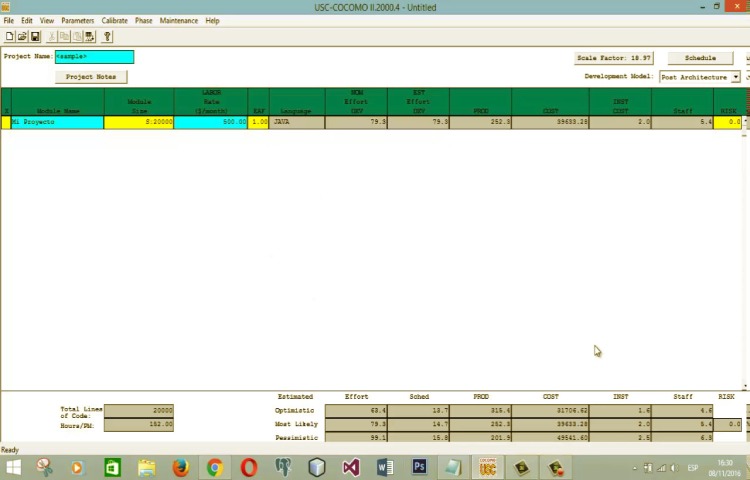
Los dos modelos COCOMO se desarrollaron en diferentes épocas de acuerdo con los avances en programación y desarrollo de software y técnicas de ingeniería, los modelos COCOMO también han evolucionado con el tiempo. El modelo COCOMO 2 es más completo en comparación a COCOMO 1. COCOMO 1 fue diseñado para software desarrollado usando lenguajes y construcciones de procedimiento, mientras que en los escenarios actuales la mayoría de los lenguajes y software se desarrollan usando paradigmas orientados a objetos para los cuales COCOMO 2 es mas apropiado.